T1.5.2 Parcours de graphes⚓︎

Algorithme de parcours
Un parcours de graphe est un algorithme consistant à explorer tous les sommets d'un graphe de proche en proche à partir d'un sommet initial.
 Parcourir simplement le dictionnaire ou la matrice d’un
graphe n’est pas considéré comme un
parcours de graphe.
Parcourir simplement le dictionnaire ou la matrice d’un
graphe n’est pas considéré comme un
parcours de graphe.
Tous les parcours suivent plus ou moins le même algorithme de base :
-
On visite un sommet s1. On note S l’ensemble des voisins de s1.
-
Tant que S n’est pas vide :
- on choisit un sommet s de S
- on visite s
- on ajoute à S tous les voisins de s pas encore visités
Sommets visités
Contrairement à un parcours d'arbre, où les fils d'un nœud ne peuvent pas avoir été visités avant le nœud, un voisin d'un sommet peut avoir déjà été visité en tant que voisin d'un sommet précédent...
Il est donc nécessaire de mémoriser les sommets déja visités ou découverts (on dira qu'un sommet est découvert lorsqu'on l'ajoute à S).
Le choix de la structure de l'ensemble S est prépondérant:
- Si on choisit une file (FIFO): on visitera les sommets dans l'ordre d'arrivée, donc les plus proches du sommet précédent. On obtient donc un parcours en largeur.
- Si on choisit une pile (LIFO): on visitera d'abord les derniers sommets arrivés, donc on parcourt le graphe en visitant à chaque étape un voisin du précédent. On obtient donc un parcours en profondeur.

1. Parcours en largeur (BFS, Breadth First Search)⚓︎
Algorithme BFS
C'est classiquement celui qu'on utilise pour trouver le chemin le plus court dans un graphe.
Exemple de parcours en largeur, avec B comme sommet de départ:
On suit l'algorithme donné plus haut, en utilisant:
- une liste
visitesqui contient les sommets visités (c'est-à-dire qu'on a fini de traiter, ici après avoir ajouté ses voisins); - une liste
decouvertsqui contient les sommets découverts au fur et à mesure du parcours; - une file
filequi contient les sommets découverts mais non encore visités. On utilisera au choix une classeFileécrite plus tôt dans l'année ou tout simplement unelistavec les méthodespop(pour défiler) etappend(pour enfiler).
En début d'algorithme, seul le sommet de départ depart donné en paramètre est découvert. La fonction BFS renvoie la liste des sommets dans l'ordre de visite lors du parcours.
| Parcours BFS - Code à compléter | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
Application: existence de chemin
L'objectif est de retrouver une chaine ou un chemin dans un graphe entre un sommet source et un sommet cible, s'il existe.
L'idée est d'ajouter dans le parcours en largeur un dictionnaire de «parentalité»: un dictionnaire dont les clés sont les sommets découverts et la valeur associée est le sommet «père», c'est-à-dire celui à partir duquel il est découvert.
Ensuite, il faut reconstituer le chemin en remontant de la cible à la source en utilisant ce dictionnaire.
-
Commencer par écrire une fonction
recupere_cheminqui prend en paramètre un dictionnaire de «parentalité», un sommet source et un sommet cible, et qui renvoie le chemin entre la source et la cible (par exemple sous forme d'une chaîne de caractères). -
Modifier la fonction BFS en ajoutant le dictionnaire
parentset en modifiant la valeur renvoyée: le chemin s'il existe,None(ou un message mentionnant qu'il n'existe pas) sinon. -
Tester sur un graphe non orienté, puis sur un graphe orienté.
Proposition de correction
2. Parcours en profondeur (DFS, Depth First Search)⚓︎
Algorithme DFS (itératif)
C'est classiquement celui qu'on utilise pour sortir d'un labyrinthe.
Exemple de parcours en profondeur, avec G comme sommet de départ:
On adapte l'algorithme BFS, avec comme (grosses) différences:
- on utilise cette fois-ci une pile
pilepour les sommets découverts mais non encore visités. On utilisera au choix une classePileécrite plus tôt dans l'année ou tout simplement unelistavec les méthodespop(pour dépiler) etappend(pour empiler); - un sommet qu'on dépile peut avoir déjà été visité! Il faut donc le vérifier avant d'examiner ses voisins.
En début d'algorithme, seul le sommet de départ depart donné en paramètre est découvert. La fonction DFS renvoie la liste des sommets dans l'ordre de visite lors du parcours.
| Parcours DFS itératif - Code à compléter | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
Algorithme DFS (récursif)
L'utilisation d'une pile peut inciter à chercher un algorithme récursif pour le parcours en profondeur, comme pour les arbres. En effet, tant qu'on peut on poursuit le parcours sur un voisin du sommet précédent... à condition que le voisin ne soit pas déjà visité!
La différence majeure avec un parcours DFS sur un arbre réside dans le fait qu'il faut stocker les sommets visités dans une liste (qu'on passera en paramètre) qui sera modifiée à chaque appel récursif. On utilise alors le caractère mutable de ce type list de Python...
| Parcours DFS récursif - Code à compléter | |
|---|---|
1 2 3 4 5 6 | |
À utiliser ainsi:
>>> DFS_rec(g, [], 'G')
['G', 'E', 'B', 'A', 'C', 'D', 'F', 'H']
Remarque
L'ordre du parcours change selon l'algorithme DFS choisi:
- avec un algorithme itératif, on utilise une pile donc le voisin choisi est le dernier;
- avec un algorithme récursif, on fait un appel récursif sur chaque voisin donc le voisin choisi est le premier.
Application: détection d'un cycle dans un graphe orienté
Dans un parcours DFS, on marque les sommets visités pour éviter de tourner en rond... Donc a priori on devrait être capable avec un tel parcours de détecter la présence d'un cycle si on retombe sur un sommet déjà visité.
Un léger problème

Comme on peut le constater, retomber sur un sommet déjà visité ne suffit pas. Il faut donc différencier les sommets «visités» en deux catégories: les sommets dont le parcours DFS est en cours, et les sommets dont le parcours DFS est terminé.
On va donc modifier le parcours DFS récursif pour lui passer deux listes en paramètres: une liste en_cours et une liste termines.
Ainsi lorsqu'on revient sur un sommet:
- de la liste
en_cours: on sait qu'on a trouvé un cycle; - de la liste
termines: on ne fait rien; - d'aucune liste: on le passe dans la liste
en_courspuis on visite récursivement ses voisins, et enfin on le passe dans la listetermines.
| Algorithme de détection de cycle - Code à compléter | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 | |
Un graphe orienté pour tester...
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
3. Exercices⚓︎
Exercice 1
-
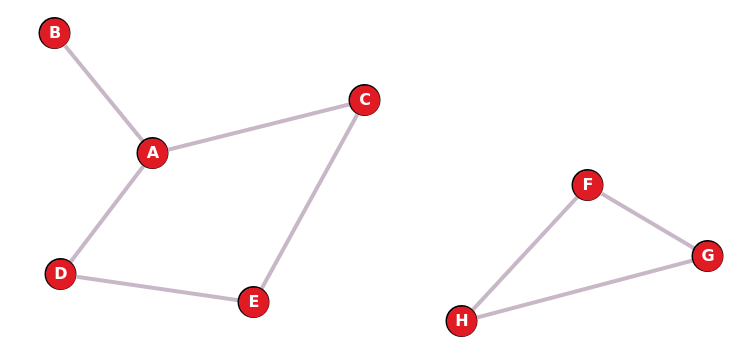
Effectuer un parcours BFS sur le graphe ci-dessous, en prenant le sommet C comme sommet de départ. Que remarque-t-on?
-
Écrire une fonction (ou une méthode)
est_connexequi détermine si un graphe est connexe ou non.
Exercice 2
Rappel
Un graphe est eulérien s'il est connexe et s'il possède exactement 0 ou 2 sommets de degré impair (le degré de sommet est son nombre de voisins).
Écrire une fonction (ou une méthode) est_eulerien qui détermine si un graphe est eulérien ou non.
Exercice 3
Si un graphe orienté est connexe, la fonction detection_cycle déterminera s'il contient ou non un cycle. En revanche, si le graphe n'est pas connexe, on ne sera pas capable de détecter un cycle dans une autre composante connexe que celle à laquelle appartient le sommet de départ.
Écrire une fonction cycle qui prend un paramètre un graphe orienté (de classe GrapheO ) et qui renvoie si le graphe contient un cycle.
Exercice 4: Algorithme de Dijkstra
L'algorithme de Dijkstra repose sur un parcours en largeur où l'on sélectionne parmi les sommets déjà découverts celui qui a la plus petite distance au sommet source.
Dans cet algorithme, on va construire un dictionnaire distances où:
- les clés sont les sommets du graphe;
-
les valeurs sont un couple (une liste) de deux élements: la distance au sommet source et le sommet «père».
Initialement, toutes les valeurs seront initialisés à
[inf, None](importerinfdu modulemathqui permet d'avoir un nombre plus grand que tous les autres), sauf pour la clé du sommet source dont la valeur sera[0, None].
On manipulera également deux listes:
- une liste
visites, initialement vide, qui contiendra au fur et à mesure les sommets visités (c'est-à-dire finis d'être traités); - une liste
decouverts, qui contient initialement le sommet source seulement, et qui contiendra les sommets accessibles par un sommet déjà traité mais non encore visités.
On suit ensuite l'algorithme suivant:
-
Tant que la liste
decouvertsn'est pas vide:- on sélectionne le sommet
s_mindedecouvertsqui a la plus petite distance au sommet source; - on supprime ce sommet
s_mindedecouvertset on l'ajoute àvisites. -
pour chaque voisin
voisinqui n'est pas visité des_min, on actualise sa distance:- s'il n'est pas dans
decouvert, on l'y ajoute et sa distance est la somme de la distance des_minà la source et du poids de l'arête reliants_minàvoisin - sinon on remplace sa distance actuelle par cette somme si elle est plus petite.
- dans les deux cas on actualise (éventuellement) le sommet père à
s_min
- s'il n'est pas dans
- on sélectionne le sommet
-
On renvoie le dictionnaire.
Remarque: on manipule un graphe de classe GrapheP...
| Algorithme de Dijkstra - à compléter | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | |
On pourra vérifier à l'aide de l'exemple sur le graphe:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | |